



Is more information better for forecast accuracy? It depends!

The more data we have the more accurate are our forecasts, typically. Unless, of course, we deal with something like a random walk model, in which case only one data point—the most recent observation—matters. In general, however, more information is better… So long as the information is relevant.
Often, we face a dilemma of whether we want to use as much information as is available, or whether we should discard the more distant data. In other words, we have to make the call about whether the older information has any value in forecasting.
If the data-generating process has not changed, then more information is a good thing for accurate forecasting. With more data, we are able to estimate the model parameters more precisely, and thus reduce the forecast error that may emerge due to parameter uncertainty.
If the data-generating process changes over time, then the use of all available data may as well harm our forecasts—they will be biased toward the historical past that is no longer relevant (e.g., think about the high interest rates of the late-1970s and early-1980s, which is a thing of a past… one would hope, at least).
The foregoing, in effect, highlights the bias-variance trade-off faced by forecasters. To illustrate the issue, consider two pseudo-forecasting routines that help us generate historical sequences of forecasts: the expanding window scheme and the rolling window scheme. The former uses all available data in generating successive forecasts (as a result, the estimation windows expand). The latter discards the earlier observations in the process (thus keeping the size of the estimation windows fixed).
Thus, the expanding window scheme relies on the assumption of no structural change. The rolling window scheme allows for the possibility of a structural change. I define “structural change” rather loosely here—it means any change in the data-generating process.
So, in this little simulation exercise, I first generate a time series that follows an autoregressive process over a given period (consisting of 480 observations—think 40 years of monthly data or 120 years of quarterly data). I then generate a time series with gradually changing parameters (of the intercept and the autoregressive term), so that the unconditional mean of the series changes over time, and so does the speed of adjustment toward this mean. I then apply expanding and rolling window schemes to both of these series.
The following graph illustrates the density of the relative difference in root mean square forecast errors—the measure of forecast accuracy—of expanding vs rolling window schemes. The forecasts are based on an autoregressive time series assuming no change in the data-generating process.
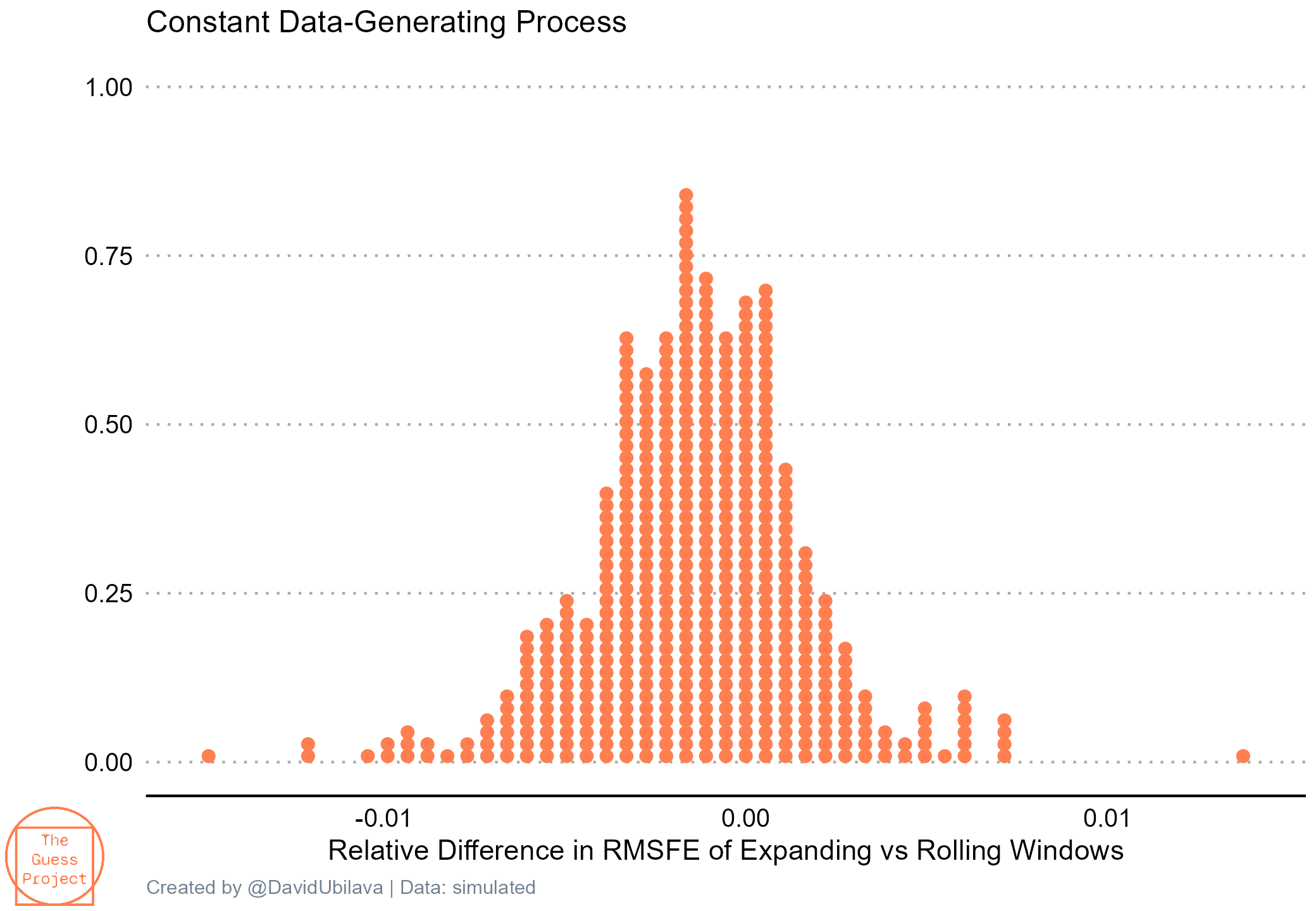
We observe that on average, forecasts generated using expanding windows are more accurate (lower RMSFE) than those generated using rolling windows. More information is better here.
The next graph illustrates a similar density from the forecasts of a time series from a time-varying data-generated process.

We observe that forecasts generated using expanding windows are much less accurate (higher RMSFE) than those generated using rolling windows. Information from a more distant past is no longer relevant. Parameters estimated from rolling windows more accurately represent the changing data-generating process.
Replication material is available here.