


I talked about the usefulness of correlations, specifically in forecasting, previously. There is more to it. This post is about some of that.
In time series analysis, we typically would like to know how correlated is a variable with its own past. Hence the name—autocorrelation.
We are interested in this because if there is such a correlation—a path dependency of sorts, that is—then we might be able to make a guess about the future by observing recent patterns of the time series.
Autocorrelations can often tell us something about the underlying time series.
No correlation
To that end, there are three broad variants of a time series. One is with no autocorrelation at any lag. A special case of it is a white noise process, which is just a bunch of zero-mean iid random variables stacked together (stochastic process). That is:
No correlation between any two y-s, regardless of how close or far away (temporally) they are from each other.
And if we draw enough of these realizations, that is if our sample is large enough, we will end up with a time series with a density that mimics that of the random variable comprising the stochastic process.
From the forecasting standpoint, our best guess for any horizon is the mean of the random variable and—by virtue of what we just discussed—the mean of the time series.
Lots of correlation
The other variant, which is (almost) on the other end of the spectrum, is a random walk process. This is a stochastically trending time series. Such a time series is highly correlated at all lags.
Stock prices, for example, are known to follow a random walk process (or to have stochastic trends). So are the prices of cryptocurrencies.
A key feature of such a time series is that it is not forecastable, which I talked about in the earlier post. What I mean by this is that we cannot predict a movement in the series based on the recently observed movement.
And, we will be observing movements. This is unlike the white noise process. In fact, a random walk, in effect, is the cumulative sum of the white noise process. That is:
We, obviously, do not observe y in period zero. So, to keep things simple, and without loss of generality, we can set it to zero. Then, at any point in time, the realization of the time series is the sum of the realizations of the mean-zero iid random variable.
Such a setup will typically yield short-term trends in the time series. These trends will be characterized by random swings due to occasional large (positive or negative) realizations of the iid random variable. Which will result in random trends (hence the stochastic trend). And owing to their random nature, none of it will matter in forecasting.
Some correlation
The final variant—perhaps the most interesting of the three—is in-between the previous two and represents a time series that follows an autoregressive process.
To begin, consider an autoregressive process of order one, or AR(1), given by:
Note that the previous two variants are special cases of AR(1). That is, when the autoregressive coefficient is 0, the model reduces to the white noise process; and when the autoregressive coefficient is 1, the model becomes the random walk process.
Being “in-between” features in the autocorrelations of the autoregressive process. Observations that are temporally close to each other, tend to be correlated. But those that are sufficiently far apart from each other—are not. Indeed, a geometric decay in the autocorrelogram is the main “giveaway” of an AR(1) process.
What about AR(p) where p>1? Similar to AR(1), observations close to each other are correlated, and those far apart from each other—are not. But unlike AR(1), we no longer have a smooth monotonic decay in the autocorrelogram.
Let’s illustrate a case using a 10-year minus 3-month interest rate spread observed at a monthly frequency from January 1982 to December 2022:

There appears to be a fair bit of autocorrelation in the series, but it doesn’t quite look like a random walk process. Let’s have a look at an autocorrelogram:

First of all, ain’t it beautiful? Anyhow, as suspected, it is likely an AR(p) process, where p>1. A partial autocorrelogram suggests an AR(3) process (Schwarz Information Criterion would confirm this)—partial autocorrelation of the first three lags are statistically significantly different from zero:
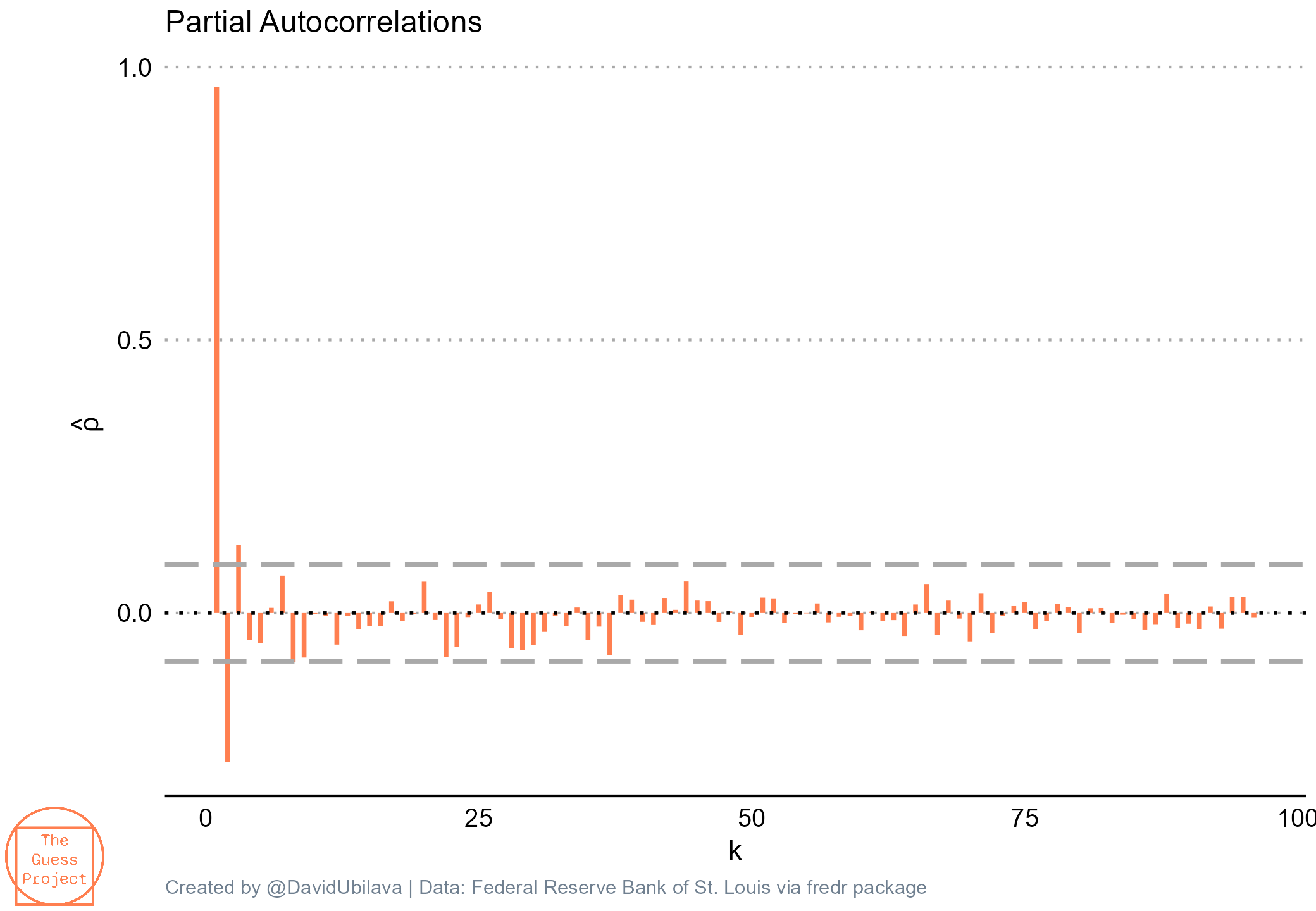
So, an AR(3) would seem to be suitable to model the interest rate spread. Would it also yield more accurate forecasts (than the random walk model)?
A pseudo-forecasting exercise
We can answer this question by dividing the series into the in-sample and out-of-sample segments and performing a pseudo-forecasting exercise. The following graph features the densities of the absolute values of the forecast errors, obtained in this way, from the random walk and AR(3) models:

There doesn’t seem to be a noticeable difference, on average, between the two sets of absolute errors. If anything, random walk appears to be more accurate. Ouch!
But this is not too surprising. The process appears to be fairly persistent (the autoregressive parameters add up to a value that is very close to one), and we likely brought in too much noise by estimating the parameters of the AR(3).
Our inability to generate more accurate forecasts from an AR(3) model doesn’t mean that the model is wrong. It just means that the model is not useful, at least not useful enough to outperform the random walk model.