

Forecasting is mostly difficult, but sometimes just not possible

Why do forecasts fail? For two broad reasons, usually. We fail to forecast either because we don’t know stuff, or because we know it all too well. The latter sounds counterintuitive. But the issue lies in our ability to influence the outcome of the variable because we were able to forecast it with reasonable accuracy. A self-fulfilling prophecy of the sort.
This alludes to the efficient market hypothesis (EMH). The EMH states that markets adjust immediately and correctly to relevant new information. As a result, a person cannot take advantage of this new information. The moment they realize they can—it’s too late.
The EMH is closely linked with the random walk hypothesis. A random walk is a manifestation of the EMH onto the prices of relevant assets. Stock prices or indices have been used to illustrate a random walk process. If stock markets are efficient, as they are believed to be, their prices follow a random walk and, thus, are unpredictable.
I will now stop talking about the stock market and start talking about a market that also largely satisfies the assumptions of the EMH. The cryptocurrency market is what I have in mind.
Can we predict cryptocurrency prices? Let’s observe Bitcoin prices from 1 January 2020 onward:
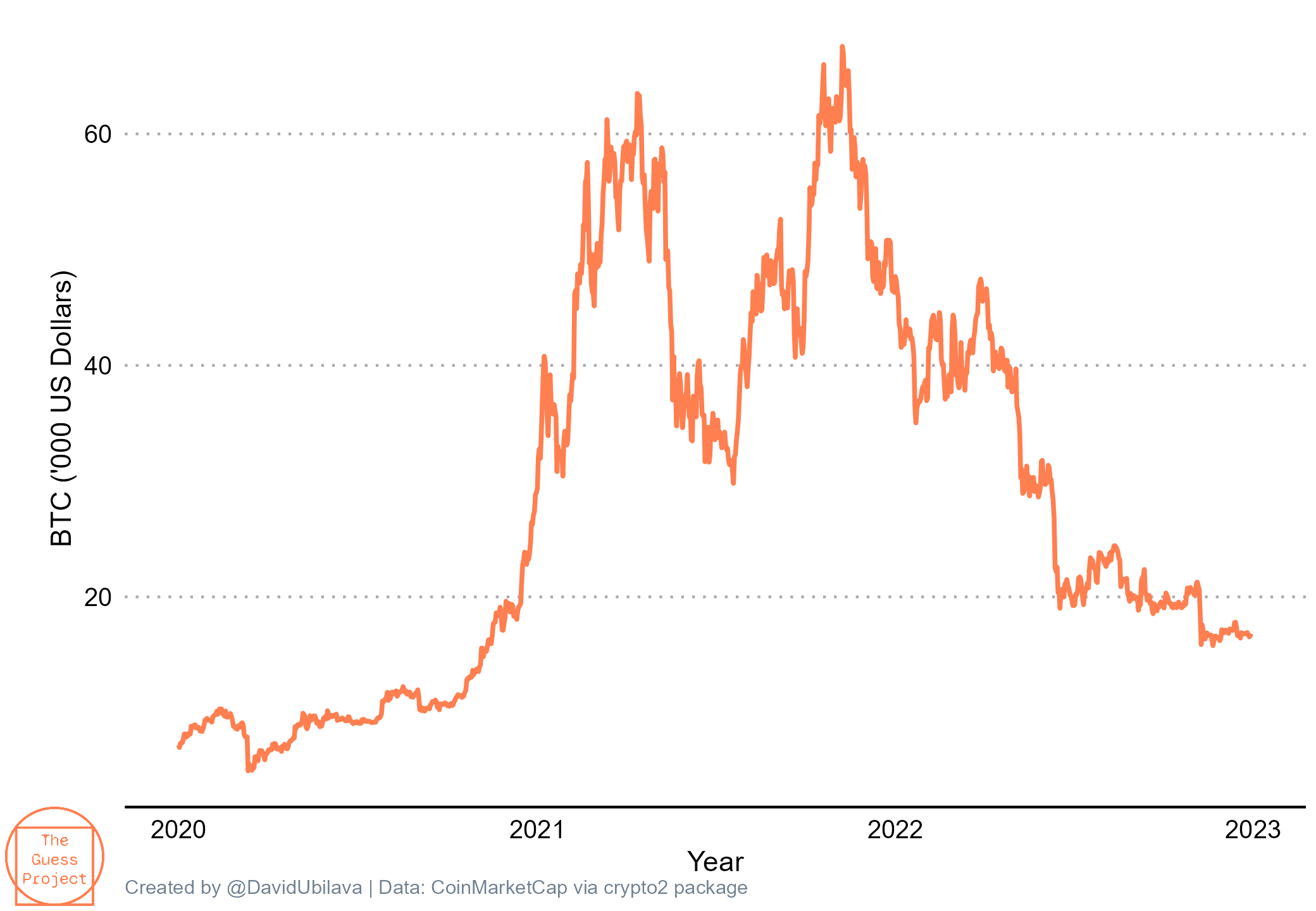
Just by looking at this graph, it seems obvious that the series is a random walk process. Another (more obvious) way to illustrate this is by constructing the so-called autocorrelogram. This is simply a sequence of correlations between a variable and its lags, also known as autocorrelations. Below I present autocorrelations of the Bitcoin price series up to lag 90 (approximately three months):
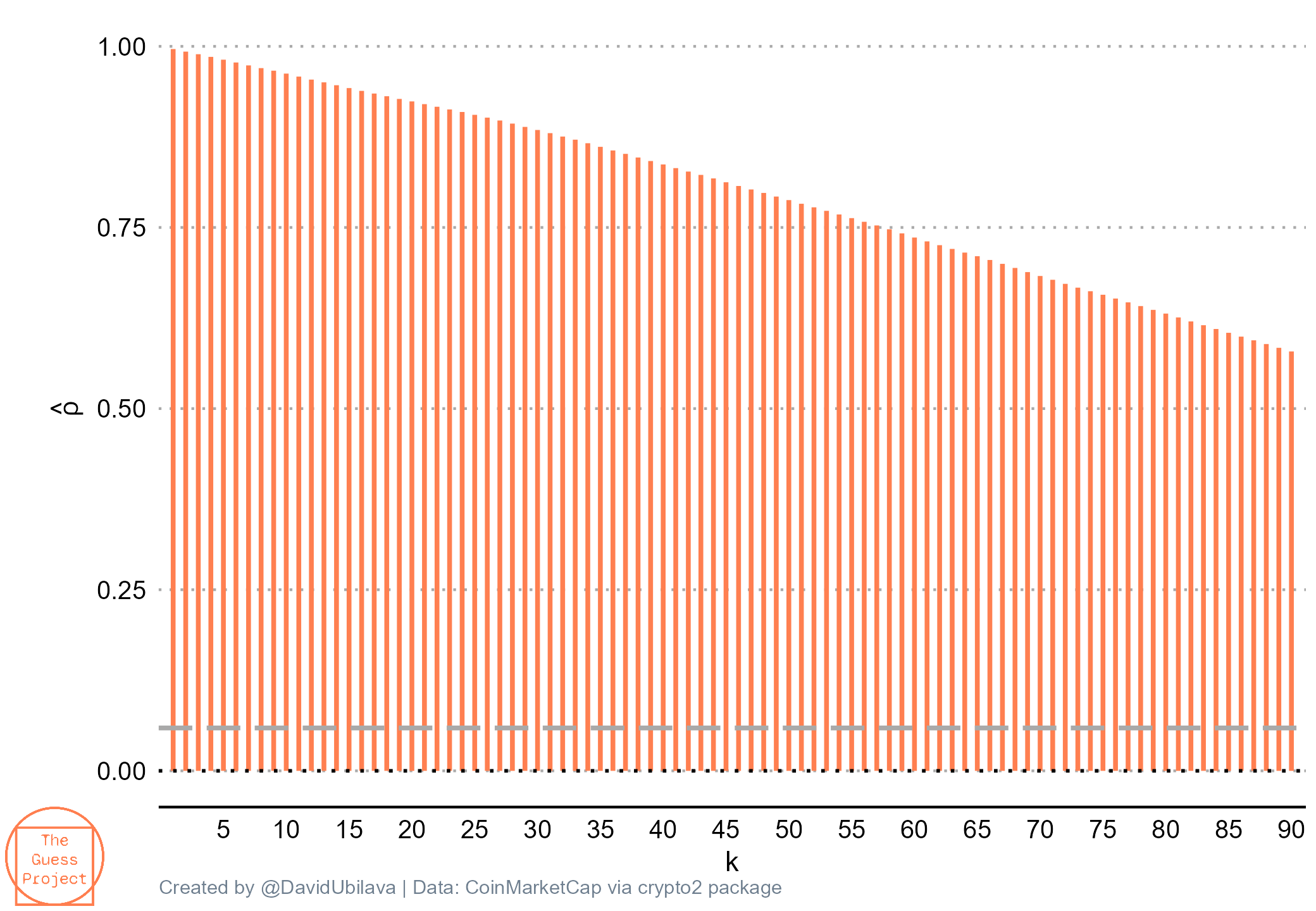
We can see that the first-order autocorrelation is very close to one. Importantly, the autocorrelogram does not quickly decay to zero. This is usually a sign of a non-stationary series, which the random walk process is.
What does this mean? This means that Bitcoin prices are meant to be unpredictable. At least, we should not be able to predict future prices by simply observing past price movements. This implies that claims that prices will increase because they have been growing, or that they will increase because prices have recently plummeted (‘buy the dip’), are mere speculation.
Because something is unpredictable doesn’t mean we cannot make a guess. We can. In the case of a random walk process, our best guess about its future value is its current value. So, if we want to challenge the EMH, we would want to beat this ‘no change’ forecast.
There are, of course, many candidate models we can assume as possible alternatives. Here, for the sake of illustration, I will use a simple (perhaps even simplistic) momentum forecast, wherein the forecast for the next period is its observed value in the current period plus the daily change from the previous period to the current period. We compare these forecasts with those of the random walk model, wherein the forecast for the next period is its observed value in the current period.
I ‘generate’ these two sets of forecasts for almost the entire period for which we have the time series. I then calculate forecast errors. These are the differences between each of the forecasts and the realized values of the prices. Below I plot the densities of the absolute values of these forecast errors:

First of all, as we can see, when we forecast, we make errors. It comes with the territory. But the random walk, on average, outperforms the momentum forecast. There are, of course, many other models one can examine in this context. A topic for another day, perhaps.
Replication material is available here.